Patterns
Linda Rising defines a pattern as “a named strategy for solving a recurring problem”. The concept of patterns comes from the work of architect Christopher Alexander, who observes “Each pattern describes a problem that occurs over and over again in our environment and then describes the core of the solution to that problem in such a way that you can use this solution a million times over without ever doing it the same way twice.”
The Deployment Pipeline
The key pattern introduced in continuous delivery is the deployment pipeline. This pattern emerged from several ThoughtWorks projects where we were struggling with complex, fragile, painful manual processes for preparing testing and production environments and deploying builds to them. We’d already worked to automate a significant amount of the regression and acceptance testing, but it was taking weeks to get builds to integrated environments for full regression testing, and our first deployment to production took an entire weekend.
We wanted to industrialize the process of taking changes from version control to production. Our goal was to make deployment to any environment a fully automated, scripted process that could be performed on demand in minutes (on the original project we got it down to less than an hour, which was a big deal for an enterprise system in 2005). We wanted to be able to configure testing and production environments purely from configuration files stored in version control. The apparatus we used to perform these tasks (usually in the form of a bunch of scripts in bash or ruby) became known as deployment pipelines, which Dan North, Chris Read and I wrote up in a paper presented at the Agile 2006 conference.
In the deployment pipeline pattern, every change in version control triggers a process (usually in a CI server) which creates deployable packages and runs automated unit tests and other validations such as static code analysis. This first step is optimized so that it takes only a few minutes to run. If this initial commit stage fails, the problem must be fixed immediately—nobody should check in more work on a broken commit stage. Every passing commit stage triggers the next step in the pipeline, which might consist of a more comprehensive set of automated tests. Versions of the software that pass all the automated tests can then be deployed on demand to further stages such as exploratory testing, performance testing, staging, and production, as shown below.
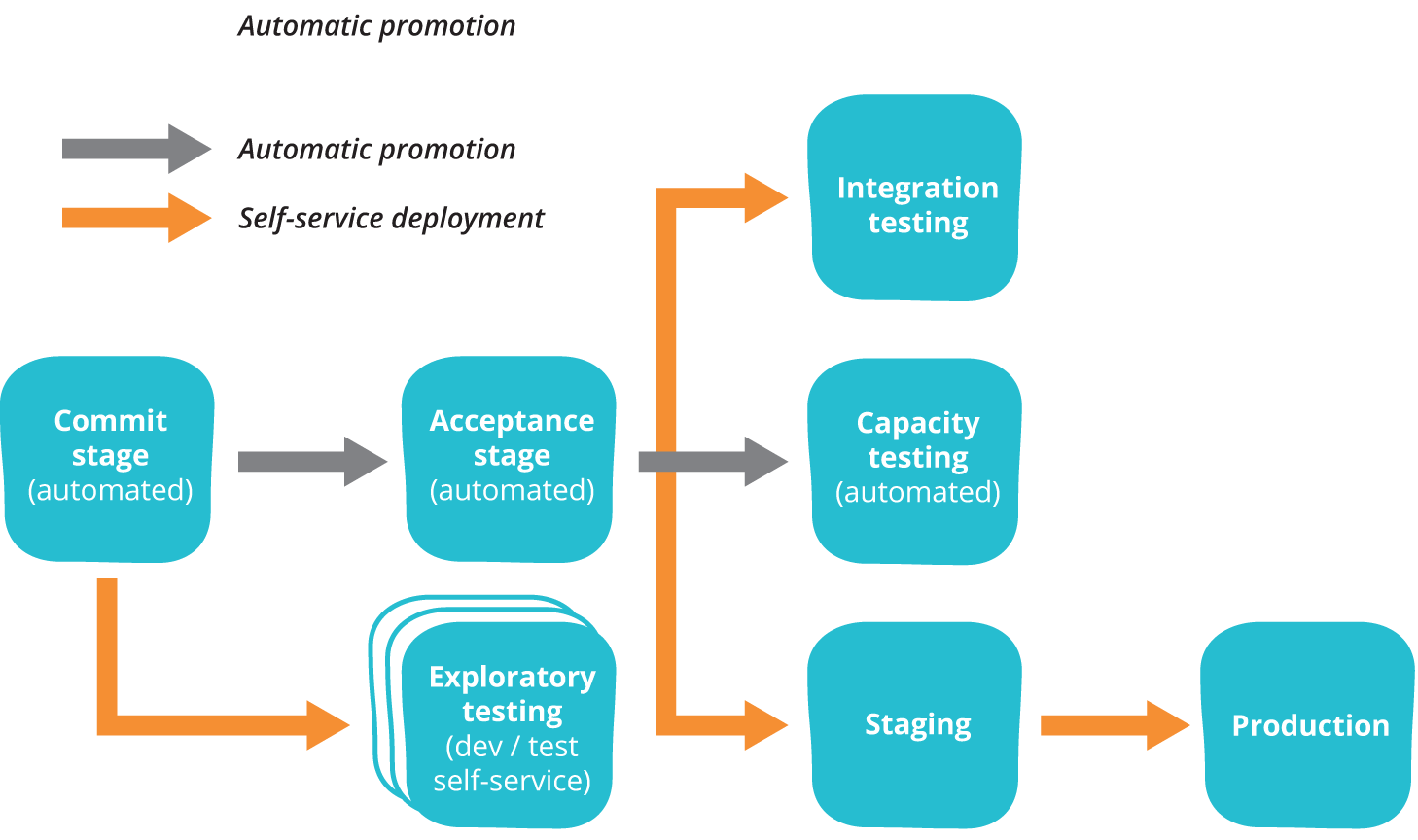
Deployment pipelines tie together configuration management, continuous integration and test and deployment automation in a holistic, powerful way that works to improve software quality, increase stability, and reduce the time and cost required to make incremental changes to software, whatever domain you’re operating in. When building a deployment pipeline, we’ve found the following practices valuable:
- Only build packages once. We want to be sure the thing we’re deploying is the same thing we’ve tested throughout the deployment pipeline, so if a deployment fails we can eliminate the packages as the source of the failure.
- Deploy the same way to every environment—including development. This way, we test the deployment process many, many times before it gets to production, and again, we can eliminate it as the source of any problems.
- Smoke test your deployments. Have a script that validates all your application’s dependencies are available, at the location you have configured your application. Make sure your application is running and available as part of the deployment process.
- Keep your environments similar. Although they may differ in hardware configuration, they should have the same version of the operating system and middleware packages, and they should be configured in the same way. This has become much easier to achieve with modern virtualization and container technology.
With the advent of infrastructure as code, it has became possible to use deployment pipelines to create a fully automated process for taking all kinds of changes—including database and infrastructure changes—from version control into production in a controlled, repeatable and auditable way. This pattern has also been successfully applied in the context of user-installed software (including apps), firmware, and mainframes. In The Practice of Cloud System Administration the resulting system is known as a software delivery platform.
Deployment pipelines are described at length in Chapter 5 of the Continuous Delivery book, which is available for free. I introduce them on this site in the context of continuous testing.
Patterns for Low-Risk Releases
In the context of web-based systems there are a number of patterns that can be applied to further reduce the risk of deployments. Michael Nygard also describes a number of important software design patterns which are instrumental in creating resilient large-scale systems in his book Release It!
The four key principles that enable low-risk releases (along with many of the following patterns) are described in my article Four Principles of Low-Risk Software Releases. These principles are:
- Low-risk Releases are Incremental. Our goal is to architect our systems such that we can release individual changes (including database changes) independently, rather than having to orchestrate big-bang releases due to tight coupling between multiple different systems. This typically requires building versioned APIs and implementing patterns such as circuit breaker.
- Decouple Deployment and Release. Releasing new versions of your system shouldn’t require downtime. In the 2005 project that began my continuous delivery journey, we used a pattern called blue-green deployment to enable sub-second downtime and rollback, even though it took tens of minutes to perform the deployment. Our ultimate goal is to separate the technical decision to deploy from the business decision to launch a feature, so we can deploy continuously but release new features on demand. Two commonly-used patterns that enable this goal are dark launching and feature toggles.
- Focus on Reducing Batch Size. Counterintuitively, deploying to production more frequently actually reduces the risk of release when done properly, simply because the amount of change in each deployment is smaller. When each deployment consists of tens of lines of code or a few configuration settings, it becomes much easier to perform root cause analysis and restore service in the case of an incident. Furthermore, because we practice the deployment process so frequently, we’re forced to simplify and automate it which further reduces risk.
- Optimize for Resilience. Once we accept that failures are inevitable, we should start to move away from the idea of investing all our effort in preventing problems, and think instead about how to restore service as rapidly as possible when something goes wrong. Furthermore, when an accident occurs, we should treat it as a learning opportunity. The patterns described on this page are known to work at scale in all kinds of environments, and demonstrably increase throughput while at the same time increasing stability in production. However resilience isn’t just a feature of our systems, it’s a characteristic of our culture. High performance organizations are constantly working to improve the resilience of their systems by trying to break them and implementing the lessons learned in the course of doing so.